
For professional translations, see my business website at www.timtranslates.com.
DownThemAll! can be a useful tool for creating a large, relatively clean corpus in a short amount of time. In this article, I shall explain one way of using DownThemAll! via a Google search to create a corpus. This particular example involves downloading the texts from the BBC Food website to create a corpus of recipes, which would be useful for translating and editing texts on food. However, the important thing is the method, rather than the result, so even if you do not think you will use a corpus on food, you may still find it useful to follow through the instructions, since you can then use the same method to download texts from other websites.
The method described in this article requires the use of the Firefox browser. The method was developed using the Windows XP operating system, but should work on other operating systems.
Firefox is needed because we will download the texts using the Firefox extension DownThemAll!. Once you have opened Firefox, if you do not already have the DownThemAll! extension, download it from here. When prompted, restart your browser (the browser should open up again with the same pages open).
DownThemAll! allows us to download all the links we have selected on a page. If we go to the BBC Recipes page and enter “chicken” into the search box, we are taken to this page. From here, we could download all 15 recipes by selecting the recipes, then right-clicking and selecting “DownThemAll selection…”, as shown below (click on pictures to enlarge).
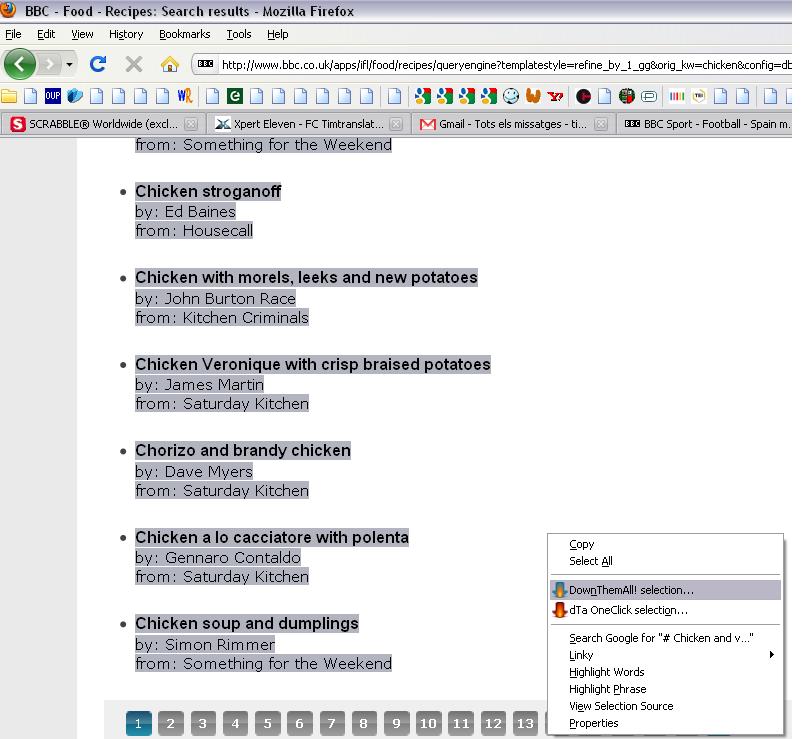
On the next screen you could then click on “All files”, select the folder to save the files to and click on “Start”. The problem with this method, however, is that we can only do 15 recipes at a time.
Downloading from Google
Google can display up to 100 results simultaneously (if anyone finds a search engine that makes it possible to display more results, please leave a comment), and we can target our search on the folder of the BBC website containing all the recipes, as follows:
- Open a new tab (press ctrl+t), open up Google, and go to “Advanced search”.
- Type +the as your search term (the plus sign tells Google to search for the word exactly as it is written, and not to ignore it as a frequent word). This should ensure we get a good range of types of recipe. If you wanted only fish or chicken recipes, then you could search for “fish” or “chicken” instead.
- Change the number of results per page to 100.
- We need to tell Google to search only within the folder containing the recipes. If you go back to the previous tab, where we searched for “chicken” in the BBC database, and move your mouse over one of the links to a recipe, you will see this folder, as shown below:

- The part I have underlined in red in the above image appears in the URLs of all the recipes. This is what we will type into Google in the “Search within a site or domain” field. Our Google search should thus appear as follows:
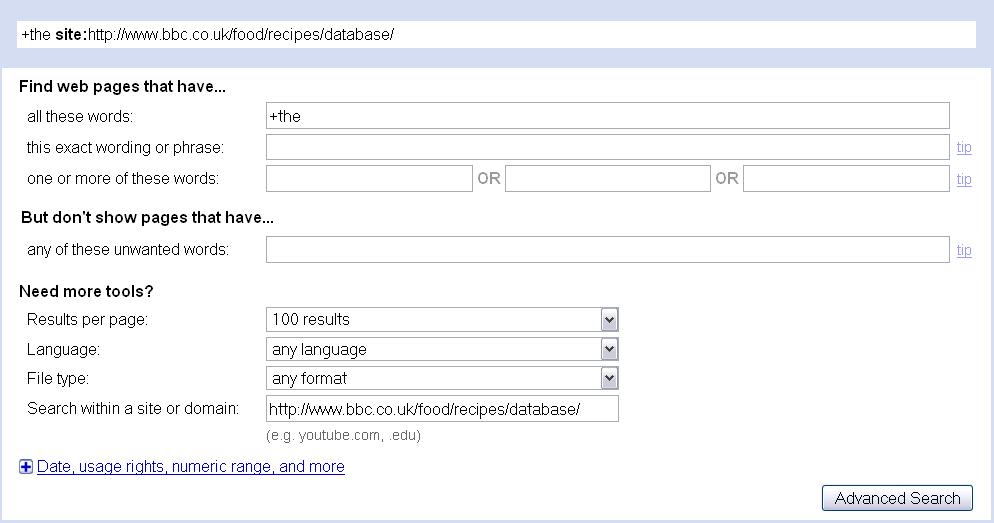
- Execute the search.
Downloading the pages
- On the results page, do not select anything, do a right-click, and click on “DownThemAll!…”.
- In the DownThemAll! window, scroll down until you can see some of the links to the actual recipes, i.e. those links with descriptions resembling those underlined in red below:
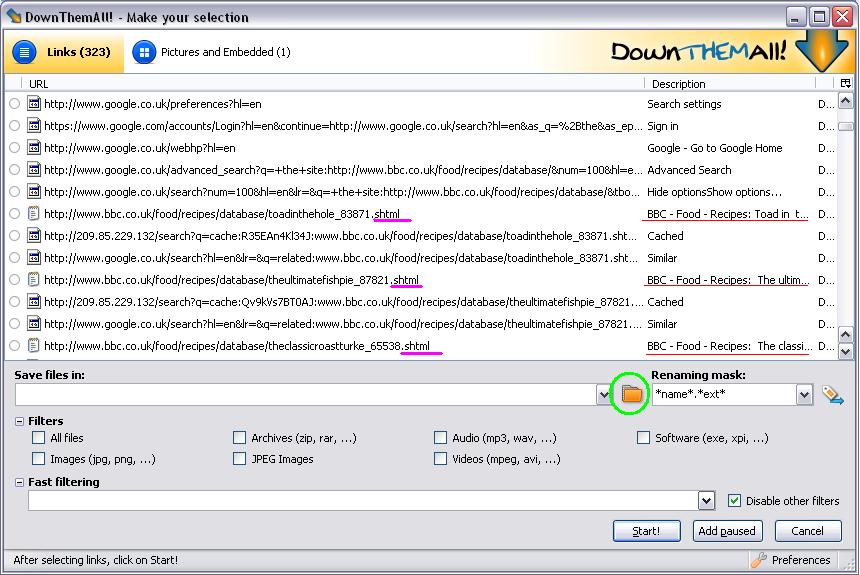
We need to find a way of downloading only the recipes, and not the Google Images, Videos, Maps, etc. links, nor the “Cached” and “Similar” links, nor any other links other than the recipes. To do this we shall use the “Fast filtering” option.
- Disable all the filters (“All files”, “Images”, etc.).
- Click on the plus sign next to “Fast filtering”
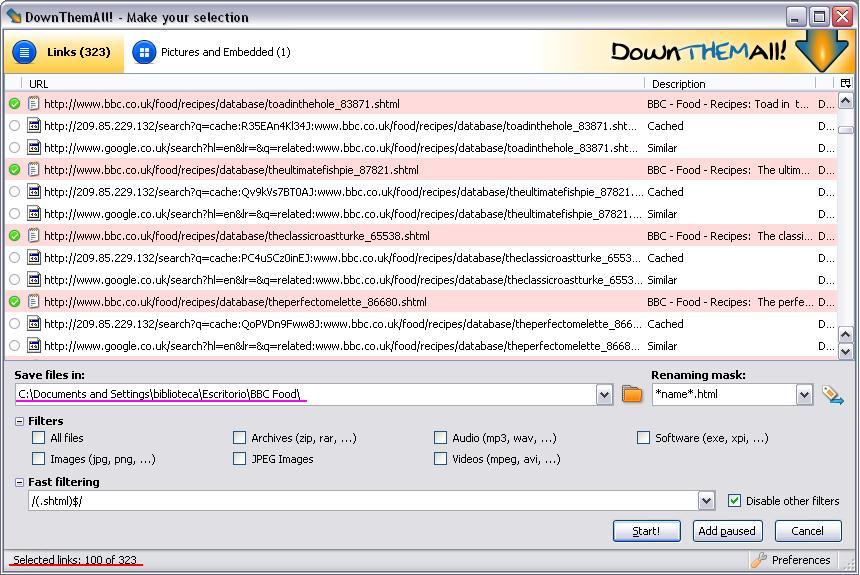
- In the “Fast filtering” box, click on the drop-down list and select the /(.mp3)$/ option. You can find more on the syntax used in the Help files, but basically this option is to select only mp3 files. In this example we want to download only “shtml” files, since our recipes contain this file extension (see the pink underlines above). Select the letters “mp3” and change it to “shtml”, since all the files we want to download have the shtml file extension. The filter should now read /(.shtml)$/
- We are going to use the renaming mask. The default mask (*name*.*ext*) means that pages will be saved with their current name and extension, so we would have files such as “theclassicroastturke_65538.shtml”. We are going to change the extension to “html”, since this will make it easier to clean our files once we’ve downloaded them. To do this, change the mask to *name*.html
- Click on the folder (circled above in green) to select where you want to save the files. Make sure you create a new folder, since we’ll be downloading hundreds of files!
- Your window should now look like the picture below, with the exception of the folder path (underlined below in pink), which depends on where you want to save the files. At the bottom of the window, as underlined below in red, it should say that you have 100 links selected.
- Click on the “Start!” button, which will bring up the download window, and start the download.
- Minimise the download window and go back to your Google search results in Firefox, then scroll to the bottom of the page and click on the number 2 to bring up results 101-200.
- Once this page has opened, do a right-click, but this time click on “dTa OneClick!” instead of “DownThemAll!”. This will start downloading results 101-200, but using the same settings as for the previous download, so this time you won’t see the settings window. After about five seconds you should see the 100/100 in the download window change to 100/200.
- You can go to the third page of Google results without waiting for the second page of results to stop downloading. Scroll down and click on the number 3, then once the page is opened, select the “dTa OneClick!” option again to download results 201-300.
- Again scroll down to the bottom, but this time we’re going to speed things up by opening the next results pages in new tabs. Click on the numbers 4 to 10 one-by-one with the middle button (scroll wheel) of your mouse, or if you don’t have this button, hold the Ctrl key on the keyboard while you click on them. Go to the first of the new tabs and select “dTa One Click!”, then do the same for each of the remaining new tabs.
Google will not let us access more than 1,000 results, but 1,000 texts will give us a pretty good-sized corpus. If you want more than 1,000 texts, then try searching for another term (such as “chicken”) and downloading again. To avoid duplicates, save to the same folder, and if the “Filename conflict” box comes up, click on Skip/Cancel and select “Just for this session”. Once you have done this, all subsequent duplicates will be ignored.
Converting to plain text
If you open one of the files you’ve downloaded in Notepad, you’ll see that the files are not very clean, and are full of html code. However, programs exist to clean this. If you use Windows, you can clean this with the appropriately named HTML2TXT (please add a comment if you know of a tool that does the same thing for another operating system):
- First, create a new folder somewhere to which we will export the cleaned files.
- Download and install Bobsoft’s HTML2TXT from here.
- When you launch the program, the “Unregistered Copy” window will appear. Click on “Try”.
- Click on “Add folder”, and the select the folder where you’ve saved the recipes. (Don’t try “Add files”, as there are too many files for this.)
- Click on the option to save the cleaned files to a new folder (highlighted in red below), then select “Click here to select” (highlighted in pink below) and choose the folder you created in the first step of this section.
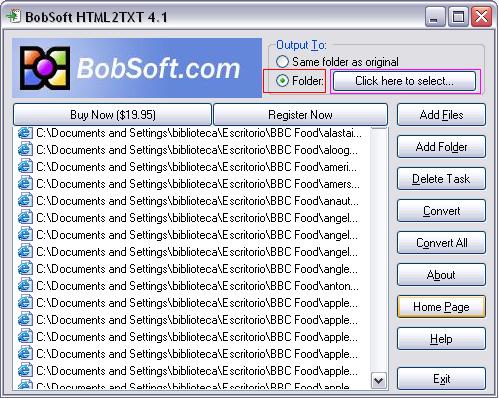
- Click on “Convert All” to convert the files. Don’t panic if the window freezes and you get a “Not Responding” message. Just be patient.
- In the new folder you will find the cleaned txt files.
Because we’ve used the demo of HTML2TXT, you will find a short message at the top of each cleaned file. This shouldn’t be a problem for most uses of corpus analysis tools (unless you want, say, accurate word counts), but if you do want to completely clean the files, you can remove this message using cheap batch find/replace tools such as FileMonkey (cost $29).
If anybody knows of free tools that do the same as HTML2TXT or FileMonkey, please leave a comment.
You now have an almost-clean corpus of recipes that you can analyse using corpus-analysis tools such as AntConc .
These instructions can be adapted to create other corpora, but certain changes will be necessary. For example, we will not always have a single file extension (such as shtml) for all the files we want to download. I hope to add further tutorials explaining how to adapt this method for other corpora, at which point I will add a link to the bottom of this page.
Please use the comments section if you have any questions or comments to make about these instructions.
I suggest HtmlAsText.exe which is free and cleanly removes html markup, simple but powerful http://www.nirsoft.net/